Have you heard of this term before? Probably not! It is NOT a fancy name for a collection of people nor some new kind of political movement.
So what is Unified Namespace (UNS), and what does it have to do with manufacturing?
 Before we dive into the specifics, let us first define what a namespace is. This term originates in the computing world and refers to a collection of similar functions that are grouped together in a way that follows a sort of logical hierarchy so they can be easily identified. If we take the example of the namespace called mathematics. This namespace would contain the collection of different maths functions such as addition, subtraction, multiplication, etc. They would also be logically structured so that all trigonometric functions are in a subgroup together, all the algebraic functions are grouped, and so on. I think you can get the picture.
Before we dive into the specifics, let us first define what a namespace is. This term originates in the computing world and refers to a collection of similar functions that are grouped together in a way that follows a sort of logical hierarchy so they can be easily identified. If we take the example of the namespace called mathematics. This namespace would contain the collection of different maths functions such as addition, subtraction, multiplication, etc. They would also be logically structured so that all trigonometric functions are in a subgroup together, all the algebraic functions are grouped, and so on. I think you can get the picture.
Now that we know what a namespace is, in general terms, let us discuss what it means in the manufacturing context. The term Unified Space was first coined by Walker Reynolds, president of 4.0 Solutions, to designate a concept that allows real-time processing and traffic of contextualised, normalised, and aggregated information. It is a central tool to fully implement the Industry 4.0 experience.
If that made your head hurt a bit, let’s go back a few steps.
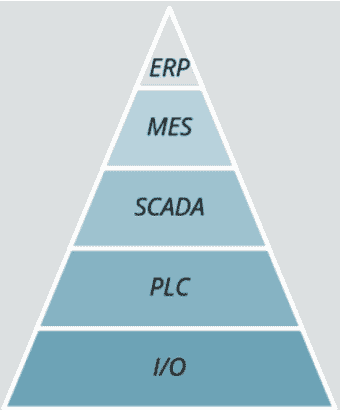 In Industry 3.0, the data flow follows what we called the automation stack. With this structure, the data flows from the bottom to the top and usually only in one direction. If you need to move certain information from your MES to your PLC, you’ll need to go through your SCADA, and then to the PLC. You cannot access and consume data by jumping over stacks. This type of data flow also limits the flexibility in terms of who generates data and who consumes it.
In Industry 3.0, the data flow follows what we called the automation stack. With this structure, the data flows from the bottom to the top and usually only in one direction. If you need to move certain information from your MES to your PLC, you’ll need to go through your SCADA, and then to the PLC. You cannot access and consume data by jumping over stacks. This type of data flow also limits the flexibility in terms of who generates data and who consumes it.
You can refer to our article about MES v SCADA to read more about this.
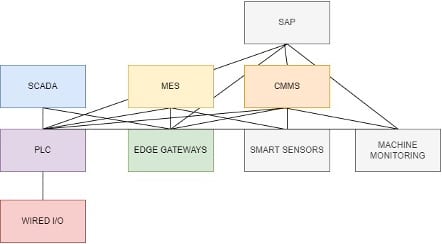 In the Industry 4.0 scene, we are trying more and more to treat each layer of the stack as nodes in our automation ecosystem. Each node is not exclusively a generator or a consumer. For example, a PLC that receives information from a machine learning system as a setpoint suggestion. As the factory expands and the need for more meaningful data becomes critical, more interfacing between nodes is required. Establishing the interface or connections between nodes costs money and time, which often leads to having a complex web of connections and if not careful, these would lead to bigger issues. So where does the Unified Namespace fit in?
In the Industry 4.0 scene, we are trying more and more to treat each layer of the stack as nodes in our automation ecosystem. Each node is not exclusively a generator or a consumer. For example, a PLC that receives information from a machine learning system as a setpoint suggestion. As the factory expands and the need for more meaningful data becomes critical, more interfacing between nodes is required. Establishing the interface or connections between nodes costs money and time, which often leads to having a complex web of connections and if not careful, these would lead to bigger issues. So where does the Unified Namespace fit in?
Here is an image that helps to explain.
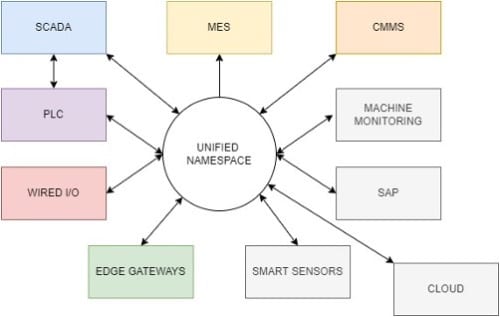 In this image, you can see that all the data flow goes into a central repository called Unified Namespace. This concept of data structure allows data to flow from each node to the Unified Namespace where data is available for consumers without needing discreet individual connections to each other. The data flow is contextualised, normalised, and aggregated information, aligning with the original intent of the concept from Walker Reynolds. What this means is the data context and structure can be set up to reflect the plant hierarchy (ISA-95) which categorises an enterprise between sites, areas and lines, equipment and sensors.
In this image, you can see that all the data flow goes into a central repository called Unified Namespace. This concept of data structure allows data to flow from each node to the Unified Namespace where data is available for consumers without needing discreet individual connections to each other. The data flow is contextualised, normalised, and aggregated information, aligning with the original intent of the concept from Walker Reynolds. What this means is the data context and structure can be set up to reflect the plant hierarchy (ISA-95) which categorises an enterprise between sites, areas and lines, equipment and sensors.
So now that we get the concept out of the way, the next question is: in the real world, how will this work?
Out in the real world, there are several solutions available. An example of this is HighByte Intelligence hub. Using this solution, you’ll be able to standardise, normalise and contextualise data.
According to Walker Reynolds, there are four main prerequisites before you can implement a system like the UNS. It needs to be:
- Edge Focused
- Report by exception
- Lightweight
- Open Architecture
More information can be found in Walker’s explanation here.
In conclusion, the UNS removes point-to-point interface, minimises the load on data transmission, and you will even find it much easier to add extra nodes. When you have a UNS system, you’ll have data that is organised, normalised and contextualised. You will be confident that “Machine A†data has the same context throughout your system
